announcement
Introducing CloudQuery SDK
Yevgeny Pats • Apr 07, 2021
Today we are pleased to announce the release of CloudQuery SDK!
We released CloudQuery at the end of last year to give developers,
SREs and security engineers a better and open-source alternative to gain deep visibility into their cloud infrastructure.
We made a few decisions like using SQL as a query and policy engine so developers won’t need to learn yet another query or policy engine!
Bonus: Reuse and take advantage of the whole huge SQL ecosystem.
CloudQuery grew over 1.3K stars in under 5 months!
This led us to develop a better and simpler way to extend CloudQuery with new resources and customs providers.
Enter CloudQuery SDK
So far adding support for new cloud providers and resources to CloudQuery required developers to implement ET (In ETL - Extract, Transform, Load).
Now, CloudQuery SDK means you as a developer will only have to implement the E (in ETL), and the SDK will take care of the rest.
Also, you will benefit from easy testable code, new features like history, policy packs and others that your providers will get out of the box as the SDK develops.
Full Documentation is available here.
For a quick snippet continue reading!
Architecture Overview
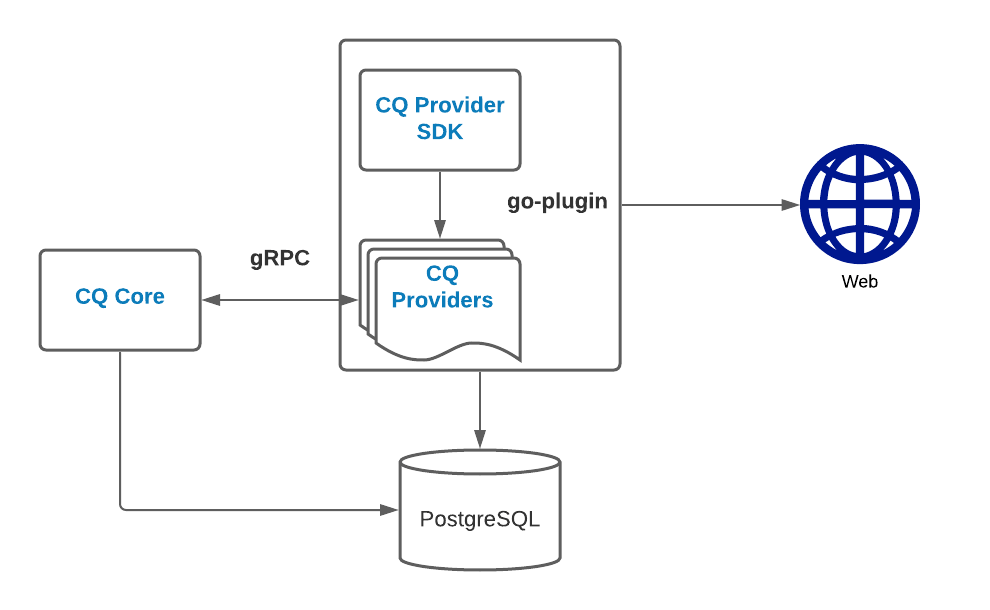
CloudQuery has a pluggable architecture and is using the go-plugin to load, run and communicate between providers via gRPC.
To develop a new provider for CloudQuery you don’t need to understand the inner workings go-plugin as those are abstracted away cq-provider-sdk.
Example
Here is a snippet of how an AWS resource implementation looks like with the new SDK
func Ec2FlowLogs() *schema.Table {
return &schema.Table{
Name: "aws_ec2_flow_logs",
Resolver: fetchEc2FlowLogs,
Multiplex: client.AccountRegionMultiplex,
IgnoreError: client.IgnoreAccessDeniedServiceDisabled,
DeleteFilter: client.DeleteAccountRegionFilter,
Columns: []schema.Column{
{
Name: "account_id",
Type: schema.TypeString,
Resolver: client.ResolveAWSAccount,
},
{
Name: "region",
Type: schema.TypeString,
Resolver: client.ResolveAWSRegion,
},
{
Name: "creation_time",
Type: schema.TypeTimestamp,
},
{
Name: "deliver_logs_error_message",
Type: schema.TypeString,
},
{
Name: "deliver_logs_permission_arn",
Type: schema.TypeString,
},
}
}
}
func fetchEc2FlowLogs(ctx context.Context, meta schema.ClientMeta, parent *schema.Resource, res chan interface{}) error {
var config ec2.DescribeFlowLogsInput
c := meta.(*client.Client)
svc := c.Services().EC2
for {
output, err := svc.DescribeFlowLogs(ctx, &config, func(options *ec2.Options) {
options.Region = c.Region
})
if err != nil {
return err
}
res <- output.FlowLogs
if aws.ToString(output.NextToken) == "" {
break
}
config.NextToken = output.NextToken
}
return nil
}Essentially you have to implement two things:
- Define how the SQL table will look like and CloudQuery will automatically get the data from the 3rd party SDK struct via default naming convention (which you can override)
- Implement the extract part of fetching the data via 3rd party SDK (In this case AWS SDK).
More Documentation available at:
What's next?
More providers, integrations and features coming up!
Subscribe to our mailing list for updates and hit that star button on our GitHub!